
Search results
There is a page named "X-means clustering" on Wikipedia
- k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which...61 KB (7,688 words) - 06:42, 1 June 2024
- process of actually solving the clustering problem. For a certain class of clustering algorithms (in particular k-means, k-medoids and expectation–maximization...20 KB (2,750 words) - 07:12, 3 May 2024
- In data mining, k-means++ is an algorithm for choosing the initial values (or "seeds") for the k-means clustering algorithm. It was proposed in 2007 by...11 KB (1,388 words) - 03:07, 19 May 2024
- clustering (also referred to as soft clustering or soft k-means) is a form of clustering in which each data point can belong to more than one cluster...14 KB (2,031 words) - 11:51, 15 May 2024
- greedy manner. The results of hierarchical clustering are usually presented in a dendrogram. Hierarchical clustering has the distinct advantage that any valid...26 KB (2,895 words) - 18:05, 3 May 2024
- k-medians clustering is a cluster analysis algorithm. It is a variation of k-means clustering where instead of calculating the mean for each cluster to determine...4 KB (487 words) - 06:47, 8 June 2024
- have a low or negative value, then the clustering configuration may have too many or too few clusters. A clustering with an average silhouette width of over...13 KB (2,108 words) - 19:58, 3 April 2024
 statistical distributions. Clustering can therefore be formulated as a multi-objective optimization problem. The appropriate clustering algorithm and parameter...69 KB (8,834 words) - 08:00, 22 June 2024
statistical distributions. Clustering can therefore be formulated as a multi-objective optimization problem. The appropriate clustering algorithm and parameter...69 KB (8,834 words) - 08:00, 22 June 2024 The general approach to spectral clustering is to use a standard clustering method (there are many such methods, k-means is discussed below) on relevant...23 KB (2,933 words) - 07:29, 11 December 2023
The general approach to spectral clustering is to use a standard clustering method (there are many such methods, k-means is discussed below) on relevant...23 KB (2,933 words) - 07:29, 11 December 2023- Clustering high-dimensional data is the cluster analysis of data with anywhere from a few dozen to many thousands of dimensions. Such high-dimensional...18 KB (2,281 words) - 22:38, 27 February 2024
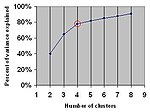 worth the additional cost. In clustering, this means one should choose a number of clusters so that adding another cluster doesn't give much better modeling...6 KB (765 words) - 15:13, 25 February 2024
worth the additional cost. In clustering, this means one should choose a number of clusters so that adding another cluster doesn't give much better modeling...6 KB (765 words) - 15:13, 25 February 2024- Medoid (category Means)Hierarchical Clustering Around Medoids (HACAM), which uses medoids in hierarchical clustering From the definition above, it is clear that the medoid of a set X {\displaystyle...33 KB (3,998 words) - 03:22, 11 June 2024
- CURE algorithm (redirect from Cure data clustering)(Clustering Using REpresentatives) is an efficient data clustering algorithm for large databases[citation needed]. Compared with K-means clustering it...6 KB (778 words) - 22:09, 29 April 2022
 Unix. X with diacritics: Ẍ ẍ Ẋ ẋ X̂ x̂ ᶍ IPA-specific symbols related to X: χ Teuthonista phonetic transcription-specific symbols related to X: U+AB56...33 KB (2,806 words) - 21:16, 16 June 2024
Unix. X with diacritics: Ẍ ẍ Ẋ ẋ X̂ x̂ ᶍ IPA-specific symbols related to X: χ Teuthonista phonetic transcription-specific symbols related to X: U+AB56...33 KB (2,806 words) - 21:16, 16 June 2024- of the clustering in the network, whereas the local gives an indication of the extent of "clustering" of a single node. The local clustering coefficient...18 KB (2,382 words) - 13:38, 30 June 2024
- BIRCH (redirect from Birch clustering method for large databases)iterative reducing and clustering using hierarchies) is an unsupervised data mining algorithm used to perform hierarchical clustering over particularly large...13 KB (2,276 words) - 16:07, 6 October 2023
- Calinski–Harabasz index (category Cluster analysis)evaluation metric, where the assessment of the clustering quality is based solely on the dataset and the clustering results, and not on external, ground-truth...7 KB (932 words) - 10:11, 19 March 2024
- DBSCAN (redirect from Density Based Spatial Clustering of Applications with Noise)Density-based spatial clustering of applications with noise (DBSCAN) is a data clustering algorithm proposed by Martin Ester, Hans-Peter Kriegel, Jörg...29 KB (3,489 words) - 17:09, 11 May 2024
- In computer science, data stream clustering is defined as the clustering of data that arrive continuously such as telephone records, multimedia data,...10 KB (1,250 words) - 06:10, 23 October 2023
- basis for clustering, and ways to choose the number of clusters, to choose the best clustering model, to assess the uncertainty of the clustering, and to...32 KB (3,523 words) - 07:43, 27 June 2024




- is made as follows: If either of the two last consonants in the cluster is [g, k, x], the inserted vowel is [o]: куски [kuskji] "pieces": кусок [kusok]
- several centuries. Chapter Three, Dynamics Of Political Economy, p. 100 The clustering of technological innovation in time and space helps explain both the uneven
- with 2 clusters of sizes 2, 2 Cluster means: X Y 1 1.5 1.0 2 4.5 3.5 Clustering vector: A B C D 1 1 2 2 Within cluster sum of squares by cluster: [1] 0